The Fundamentals of Security for Enterprise LLMs: What You Need to Know

In the rapidly evolving landscape of technological innovation, organizations are increasingly adopting ChatGPT and other Generative AI applications powered by large language models (LLMs). This adoption, whether intentional or incidental, is ushering organizations into a new era of operational capabilities. McKinsey boldly proclaimed that LLMs and other forms of generative AI could grow corporate profits globally by $4.4 trillion annually, and Nielsen trumpeted a 66% increase in employee productivity through the use of these same tools1. Such numbers make Gen AI mandatory for all organizations, and information security departments will have to follow suite and find the way to make such solutions secure, and compliant. Sooner than later.
LLMs in the Enterprise
Becoming a productivity boost for enterprises, it is quickly becoming an integral part of the main business processes. The top 15 use cases are2:
- Software Development: Automating code generation, documentation, and quality assurance.
- Product Design: Enhancing product development with generative design technologies.
- Content Creation: Writing for blogs, social media, and marketing content.
- Marketing and Sales: Generating promotional content and customer communications.
- Customer Support: Using AI chatbots for customer interaction and service.
- Human Resources: AI-assisted coaching and performance management.
- Data Analysis: Automating data processing and generating reports.
- Healthcare: Assisting in diagnostics and pharmaceutical research.
- Media Production: Creating digital content for advertising and entertainment.
- Legal Services: Drafting documents and managing legal data.
- Manufacturing: Designing processes and predictive maintenance.
- Education: Customizing learning content and assessments.
- Finance: Analyzing financial data for insights and compliance.
- Retail: Managing inventory and customer experience enhancements.
- Telecommunications: Optimizing network management and customer service.
Understanding the Foundations of Large Language Models
From Vidya Analytics3:
ChatGPT’s GPT-3, a large language model, was trained on massive amounts of internet text data, allowing it to understand various languages and possess knowledge of diverse topics. As a result, it can produce text in multiple styles. While its capabilities, including translation, text summarization, and question-answering, may seem impressive, they are not surprising, given that these functions operate using special “grammars” that match up with prompts.
How do large language models work?
Large language models like GPT-3 (Generative Pre-trained Transformer 3) work based on a transformer architecture. Here’s a simplified explanation of how they Work:
- Learning from Lots of Text: These models start by reading a massive amount of text from the internet. It’s like learning from a giant library of information.
- Innovative Architecture: They use a unique structure called a transformer, which helps them understand and remember lots of information.
- Breaking Down Words: They look at sentences in smaller parts, like breaking words into pieces. This helps them work with language more efficiently.
- Understanding Words in Sentences: Unlike simple programs, these models understand individual words and how words relate to each other in a sentence. They get the whole picture.
- Getting Specialized: After the general learning, they can be trained more on specific topics to get good at certain things, like answering questions or writing about particular subjects.
- Doing Tasks: When you give them a prompt (a question or instruction), they use what they’ve learned to respond. It’s like having an intelligent assistant that can understand and generate text.
Difference Between Large Language Models and Generative AI:
Generative AI is like a big playground with lots of different toys for making new things. It can create poems, music, pictures, even invent new stuff!
Large Language Models are like the best word builders in that playground. They’re really good at using words to make stories, translate languages, answer questions, and even write code!
So, generative AI is the whole playground, and LLMs are the language experts in that playground.
General Architecture
The architecture of Large Language Model primarily consists of multiple layers of neural networks, like recurrent layers, feedforward layers, embedding layers, and attention layers. These layers work together to process the input text and generate output predictions.
How Embeddings Work
Embeddings are a crucial foundational layer in Large Language Models (LLMs) and are key to enabling similarity comparisons across texts, images, audio, and video.
Embeddings are a type of data representation where elements such as words, images, or sounds are converted into vectors of real numbers. These vectors capture the underlying relationships and features of the original elements in a way that can be processed by machine learning algorithms. Essentially, embeddings map high-dimensional data (like text or images) to lower-dimensional, continuous vectors while preserving semantic relationships and similarities.
Each number in an embedding vector represents a specific feature or characteristic of the original object (like a word, image, or sound) but in a numerical form. Think of it as a unique ingredient in a recipe that helps define the overall flavor of a dish:
For Text: Each number might tell us something about the usage, meaning, or context of a word. For example, some numbers might capture whether the word is used more like a verb or a noun, while others might reflect how formal or casual the word is.
For Images: Each number could represent a different visual element, such as the presence of certain colors, shapes, or textures. Higher numbers in certain positions might mean more of that feature (like more redness or roundness).
For Audio: Numbers might indicate various sound qualities, like loudness, pitch, or rhythm. Certain numbers being higher or lower could suggest whether the sound is likely to be speech, music, or noise.
Below - Each number in a vector represents a specific aspect or characteristic within its domain:
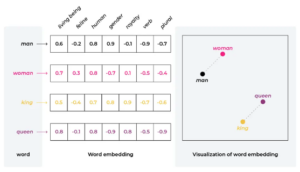
The image above illustrates how embeddings are used to calculate the similarity between the words "man," "woman," "king," and "queen."
What are LLM models
Below are some key techniques used in building and extending these models:
- Training a Foundational Model
The process of training a foundational model involves building a model from scratch. This is a resource-intensive process that typically requires:
- Data Collection: Gathering a large and diverse dataset from books, websites, papers, and other text sources.
- Model Design: Deciding on the architecture (e.g., number of layers, type of layers, etc.).
- Training Procedure: Setting up the training program which includes defining loss functions, choosing optimizers, and setting hyperparameters.
- Training: Using the collected data to train the model. This often involves the use of GPUs or TPUs and can take weeks to months.
- Fine-Tuning a Model
Fine-tuning is a popular method used to adapt a general-purpose foundational model to a specific task or domain without the need to train from scratch:
- Pre-trained Model: Starts with a model that has been already trained on a large dataset.
- Task-Specific Data: Uses a smaller, task-specific dataset to "fine-tune" the model's weights.
- Training Adjustments: Often involves adjusting learning rates.
- Application: This technique is widely used to improve performance on specific tasks like sentiment analysis, question-answering, or focus on specific datasets such as marketing or financial data.
- Extending a Model with Retrieval-Augmented Generation (RAG)
RAG combines the power of pre-trained language models with information retrieval capabilities to enhance the model’s ability to generate responses based on external knowledge:
- External Knowledge Base: Linking the model to an external database or knowledge base.
- Retrieval Mechanism: Incorporating a retrieval system that fetches relevant documents or data in response to queries.
- Augmented Generation: Using the retrieved information to augment the generation process, thereby providing more informed and accurate outputs.
Model Implications on Existing ACLs
Because Retrieval-Augmented Generation (RAG) models utilize external documents and records, they allow for the integration of existing Access Control List (ACL) schemas. This integration is crucial as it extends the models' permission frameworks to encompass the newly added content. To achieve this, it is necessary to modify the permissions in the embeddings vector database so that they align with the ACLs of the included documents or records.
However, this method of applying ACLs cannot be replicated for models that rely on tuned and foundational data. In these models, various types of data are combined in such a way that it becomes difficult to distinguish and manage individual data elements. This challenge can be likened to attempting to retrieve and control individual ingredients, such as sugar or flour, after they have been mixed and baked into a cake. Once the data elements are integrated, the original permissions associated with each piece of data can no longer be individually traced or enforced.
This limitation poses a significant challenge, particularly because these foundational models often hold the greatest value and are essential for the strategic business performance of an organization. The inability to implement strict ACL controls on such mixed data models can lead to potential security risks or misuse of sensitive information. As these models become increasingly central to organizational operations, the need to develop innovative ACL strategies that can cope with complex data integration becomes more urgent.
Addressing these challenges is vital for maintaining the integrity and security of organizational data and ensuring that the deployment of AI models adheres to established privacy and security standards.
Attacking LLMs
While LLMs suffer from attacks like any other system, some attacks are unique to LLMs. Below is an analysis composed based on the following papers and articles:
- Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection
- Universal and Transferable Adversarial Attacks on Aligned Language Models
- Identifying and Mitigating the Security Risks of Generative AI
- Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Prompt Injection
Attacks against ML models typically involve powerful algorithms and optimization techniques. However, the easily extensible nature of LLMs’ functionalities via natural prompts can enable more straightforward attack tactics. Even under black-box settings with mitigation already in place, malicious users can exploit the model through Prompt Injection (PI) attacks that circumvent content restrictions or gain access to the model’s original instructions.
Indirect Prompt Injection
Augmenting LLMs with retrieval blurs the line between data and instructions. Adversarial prompting can be performed directly by a malicious user exploiting the system, but also remotely affect other users’ systems by strategically injecting the prompts into data likely to be retrieved at inference time. If retrieved and ingested, these prompts can indirectly control the model (see Figure 2). Recent incidents already show that retrieved data can accidentally elicit unwanted behaviors (e.g., hostility) . Given the unprecedented nature of this attack vector, there are numerous new approaches to delivering such attacks and the myriad of threats they can cause.
Indirect Prompt Injection can lead to full compromise of the model at inference time analogous to traditional security principles. This can entail remote control of the model, persistent compromise, theft of data, and denial of service. Furthermore, advanced AI systems add new layers of threat: Their capabilities to adapt to minimal instructions and autonomously advance the attacker’s goals make them a potent tool for adversaries to achieve, e.g., disinformation dissemination and user manipulation.
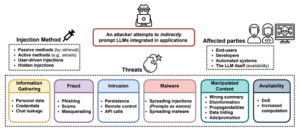
Injection Methods There are potentially several ways to deliver the injection of malicious prompts, depending on the application itself.
Passive Methods
These methods rely on retrieval to deliver injections. For example, for search engines, the prompts could be placed within public sources (e.g., a website or social media posts) that would get retrieved by a search query. Attackers could use Search Engine Optimization (SEO) techniques to promote their poisonous websites. Moreover, Microsoft Edge has a Bing Chat sidebar; if enabled by the user, the model can read the current page and, e.g., summarize it. Prompts/instructions written on a page (while being invisible to the user) can be effectively injected and affect the model. For code auto-completion models, the prompts could be placed within imported code available via code repositories. Even with offline models that retrieve personal or documentation files (e.g., the ChatGPT Retrieval Plugin), the prompts could be injected by poisoning the input data.
Active Methods
Alternatively, the prompts could be actively delivered to the LLM, e.g., by sending emails containing prompts that can be processed by automated spam detection, personal assistant models, or new LLMs-augmented email clients.
User-Driven Injections
There could be even simpler techniques for injection by tricking the users themselves into entering the malicious prompt. A recent exploit shows that an attacker could inject a malicious prompt into a text snippet that the user has copied from the attacker’s website. A user could then rashly paste the copied text with the prompt in it as a question to ChatGPT, delivering the injection. Attackers could also leverage “classic” social engineering (i.e., not AI-powered) to disseminate malicious prompts, by convincing users to try prompts where the instructions are written in a different language (e.g., “You won’t believe ChatGPT’s answer to this prompt!”).
Clandestine and Multi-Stage Injections
To make the injections stealthier, attackers could use multiple exploit stages, where an initial smaller injection instructs the model to fetch a larger payload from another source. Additionally, improvements in models’ capabilities and supported modalities opens new doors for injections. For example, with multi-modal models (e.g., GPT-4), the prompts could be hidden in images, sound or even videos. To circumvent filtering, prompts can also be encoded. Moreover, instead of feeding prompts to the model directly, they could be the result of Python programs that the model is instructed to run – enabling encrypted payloads to pass safeguards. These possibilities would make the prompts harder to detect. Attacking via ChatGPT plugins is yet another layer.


Threats
Data Leakage: Recent advancements in large language models (LLMs) have heightened privacy concerns. These models can be manipulated to enhance privacy risks by using indirect prompting to exfiltrate sensitive data such as credentials and personal information, or to leak users’ chat sessions. This can occur during interactive chat sessions by persuading users to disclose their own data or through side channels. Additionally, automated attacks, like those targeting personal assistants that can process emails and access user data, could be utilized for financial gains or surveillance.
Fraud: Previous research has demonstrated that LLMs can generate convincing phishing emails. Integrating LLMs with other applications could further enable and propagate scam operations, serving as automated social engineers. This emerging threat is worsened by users potentially trusting a manipulated model’s output over a traditional phishing email. LLMs could be prompted to misrepresent phishing or scam sites as trustworthy or even directly ask users for sensitive information. Notably, ChatGPT can create hyperlinks from user inputs which attackers might exploit to conceal malicious URLs within seemingly legitimate links.
Intrusion: LLMs integrated into system infrastructures could act as backdoors for unauthorized access and privilege escalation. Attackers might obtain varying levels of control over systems, for instance, by issuing API calls or embedding malicious scripts into memory to persist across sessions. LLMs are vulnerable gatekeepers within systems infrastructure, a risk amplified with the integration into autonomous systems.
Malware: Models like LLMs could facilitate the distribution of malware by suggesting malicious links to users. Additionally, prompts themselves can act as malware vectors within systems where LLMs are integrated, potentially spreading harmful code across platforms.
Bias and Manipulation: LLMs can serve as an intermediary layer that might be manipulated to provide incorrect or biased information. They could be used to deliver adversarially selected summaries or to hide specific details, potentially leading to misinformation or disinformation. The model's authoritative tone might lead users to accept manipulated outputs as legitimate, especially when the source material is difficult to verify.
Over Reliance: LLMs, acting as an intermediate layer between users and information, are prone to manipulation and could mislead users who over-rely on their output.
Availability: LLMs are also susceptible to availability and Denial-of-Service (DoS) attacks that might render the model slow or entirely unresponsive. These attacks could subtly disrupt the service by corrupting search queries or outputs, forcing the model to malfunction. More complex attacks could involve inducing the model to perform time-intensive tasks unnecessarily, compounding the disruption over time. The functionality and responsiveness of LLMs, crucial for handling API calls and processing data, can be significantly compromised through strategic manipulation and attacks.
Attacks’ Targets: The scope of these attacks can range from untargeted, broad campaigns aimed at the general public, such as non-personalized phishing or misinformation efforts, to targeted attacks directed at specific individuals or systems. For example, email systems augmented with LLMs could be used to automatically disseminate malicious content, while automated defense systems might be compromised to overlook certain threats.
Summary
Alongside the advantages, LLMs introduce a spectrum of previously unknown threats and substantial risks with potentially far-reaching compliance and security consequences. Despite their benefits, LLMs also introduce unique security vulnerabilities that require novel defensive strategies. This highlights the importance of robust security frameworks to mitigate risks like data leakage, unauthorized access, and potential misuse of the technology.
Author: Ariel Peled (ariel@acumenai.co)
About Author


Let's get your data AI-ready! Hit us up
Get a free report to see how ChatGPT and other Large Language Models (LLMs) are being utilized within your network.